Autonolas & Co-Owned AI (zkML & SMPC)
This article aims to provide an introduction to zero knowledge machine learning, distributed machine learning, secure multi-party computation, and how they can be used within the Autonolas stack (Open AEA & Open Autonomy) in the form of agent services.
Included also is a simple demo showing the possibilities in the form of code snippets. For more information on Autonolas and multi agent system architectures, read previous articles written by the community/creators or check out Valory’s Github & the Autonolas documentation.
Preliminary Knowledge
So What Is “Zero Knowledge Cryptography”?
Zero knowledge cryptography was invented in the mid 1980s (see The Knowledge and Complexity of Zero Knowledge Proofs) Since then, especially in the past decade, there has been lots of progress on its applications.
The general framework of ZKP systems comprises of a “statement” made by a “prover” party that must be proven true with overwhelming probability to a “verifier” party without revealing/passing additional information about the statement’s creation during the verification process other than the correctness of the proof (true or false).
This is assuming none of the parties involved have the resources to produce true outputs from false statements because their computational power is bounded.
- Statements: At a high level, statements can be viewed as a composition of information/data that make up 3 main components:
- Public inputs: data of universal access that both the prover and verifier party know (for example a public key, or a public hash of something)
- Private inputs: data that the prover party has but wants to keep secret (for example a private key, or a pre-image of some hashed data that is public)
- Assertion(s): This is the part of the statement where claims made by the prover’s submitted proof containing all inputs, public or private, are given to the verifier for verification.
- Prover: The party that constructs the “proof” given all inputs and assertions about those inputs that make up the proof’s logic, and then sends it to the verifier. Generally the most resource intensive part of the process.
- Verifier: The party that verifies the “proof” given by the prover, thereafter doing a series of checks that involve data contained in the proof object. Generally verification is less resource intensive than proving and that is by design.
- Proof: At a high level you can think of the “proof” as a collection of inputs that form a root hash of some computational process that makes up the entire proof system.
Interactive vs Non-Interactive Proof Systems
Non-interactive: non interactive zero knowledge proof systems are designed in such a way that the prover party generally has significantly more resource requirements than that of the verifier. The prover generates a single proof which is then verified by the verifier. This can make the verification process more trivial which can be useful in many cases to avoid communication overhead as well as the other advantages when compared to interactive proof systems. The disadvantage is that total resource requirements are typically greater than that of interactive proof systems. Check out the Fiat Shamir Heuristic for more.
Interactive: Interactive zero knowledge proof systems are designed in such a way that both the prover and verifier spend similar amounts of compute resources while communicating back and forth with one another. The prover and verifier go through several rounds where the prover will send a message to the verifier.
The verifier will then send back a “challenge” to the prover’s message which the prover then uses to formulate a response. This process continues until the proof system runs to completion. The main advantage with interactive proof systems is that they end up requiring less compute resources overall but involve more communication overhead as a result.
Limitations & The Future
Generating zero knowledge proofs is very expensive with today’s technology, many magnitudes more expensive than the original computation one could try to prove with it. For this reason, a few of the sub-domains of computer science/engineering generally, have shown to be impractical with regard to the amount of time needed to add ZKP systems on top of the base computation they would validate and/or keep secret. As we continue to see large amounts of improvement in computer hardware, cryptography, and distributed systems capabilities we will see more and more use cases of ZKP systems becoming practical in production applications.
What Is Machine Learning?
Machine learning (ML) is a subset of artificial intelligence (AI) that centers around designing software algorithms/applications targeted at accuracy or optimization problems without being explicitly programmed to do so. Hence the key word “learning”.
Machine learning models are constructed explicitly in their architecture, but depending on said architecture, the execution of the model and features of the model’s architecture can change overtime given how it is “trained”, what it “learns”, and what it has the ability to change by itself.
The general value proposition of machine learning is, more effective automation and greater/different types of intelligence. Applied machine learning can make the economy more efficient and solve more complex problems that take a tremendous amount of information/understanding to improve upon or solve.
Examples of popular AI/ML models:
- GPT-4 (chatGPT), which is a generalized language model designed to provide inputs in the form of text to text outputs, AKA written conversation.
- DALL-E 2 & Stable Diffusion, generalized text to image models
- MNIST image classifier (Convolutional Neural Network)
Zero Knowledge Machine Learning
zkML refers to the application of cryptography & more specifically, zero knowledge cryptography inside specific steps of a given machine learning model’s architecture. Use cases can vary greatly in their technical implementation, but at a high level, the cryptography is used to hide model inputs (data), model outputs (inference on the data) or also parts of the model’s execution.
Based on existing research and current open source zkML projects (check out awesome-zkml) efforts have been focused mainly on making the inference step of the ML model private, making the input data itself private, as well as validating the computation of a model’s inference step using various proof systems.
As for applying cryptography to the model’s training process, it is still very much infeasible given today’s level of computer hardware & software performance as this is the most computationally intensive part of machine learning model’s.
Worldcoin has a great Venn diagram here breaking down each subcategory of what is generally referred to as “zkML” projects and how they intersect with one another:
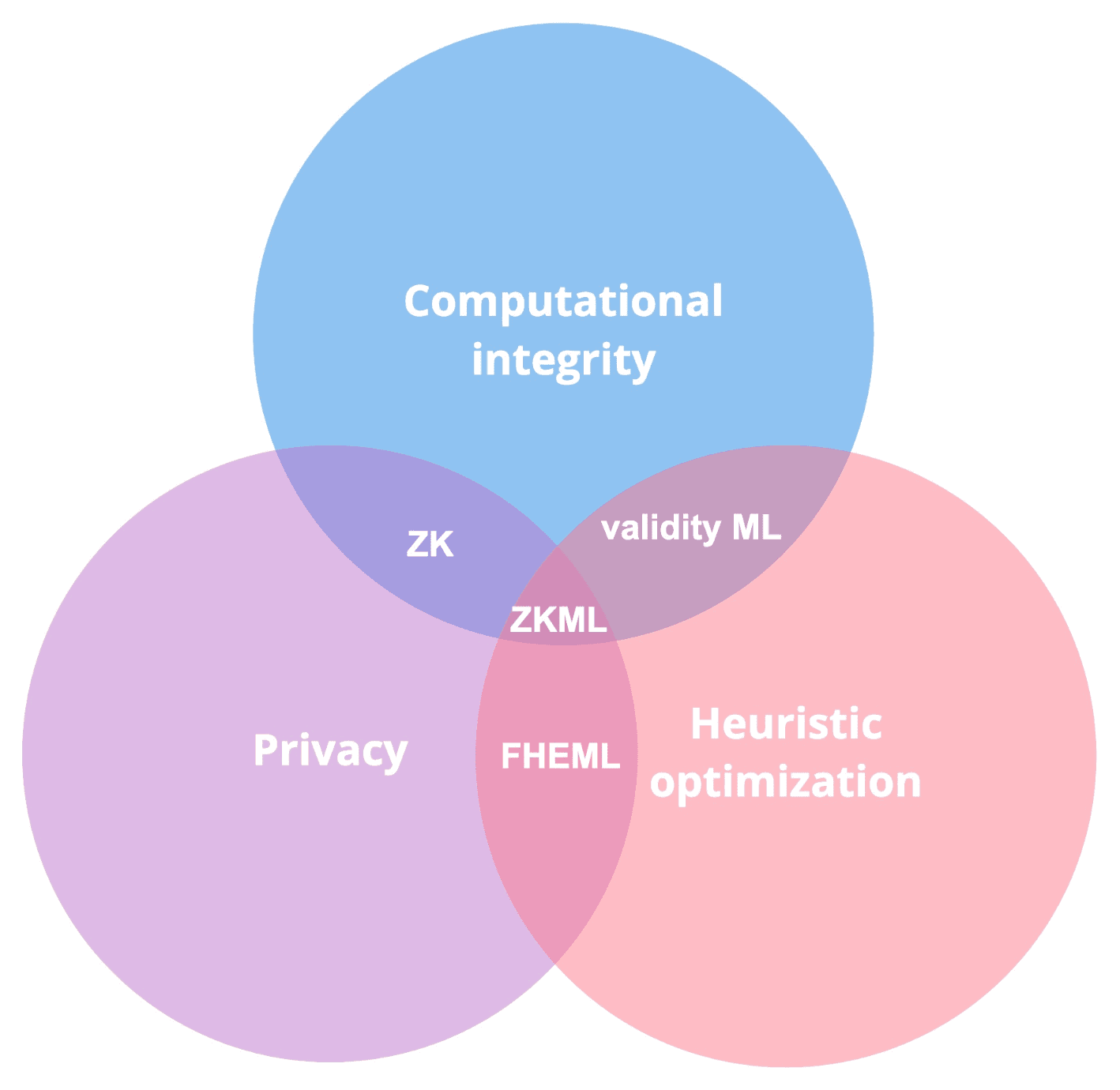
Zero Knowledge vs Validity proofs
ZKPs fall under the canopy of “validity” proofs in that they validate computational integrity by means of cryptographic proof, but in order to be truly “zero knowledge” the proof must not reveal anything else to the verifier about the statement made by the prover, other than its computational correctness. Notice ZK in the Venn diagram above is the intersection between computational integrity and privacy. Whereas with validity proofs, they use the same underlying mathematical framework as ZKPs to form statements made by a proving party, but these statements do not have to be fully private from the perspective of the verifier.
Validity ML:
Validity proofs of ML model executions generated by a prover that proves computational correctness to a verifier.
Zero Knowledge ML:
Zero knowledge proofs of ML model executions generated by a prover that proves computational correctness and keeps everything about the inference step of the ML model private from the perspective of the verifier, verifying the proof.
Fully Homomorphic Encryption (FHE) ML:
FHE allows for operations to be performed on encrypted data without having to decrypt it until after an operation is complete, in which a specific party (only that party) can decrypt the output from the operation afterwards. In the context of FHE ML this allows for information to be kept private.
Autonolas & Multi-Agent Systems (MAS)
Multi agent systems frameworks (for example Open AEA & Open Autonomy) allow for some incredibly powerful ideas to take shape. The overarching benefits of using agent based software frameworks at a high level are born out of the ability to standardize communication between a distributed group of “agents’’ using a highly modularized set of “components’’ stored in a public “registry”.
As a result of how MAS frameworks are designed, one can build applications that could run virtually anything from individual actions run by a single agent or a network of agents running an “agent service”.
For a more detailed dive into agents see the Open AEA documentation and for agents services see the Open Autonomy documentation.
High level definitions:
Agents: Agents built with Open AEA (Autonomous Economic Agents) can be viewed as code runtimes (Python programs for example) that are continuously running until otherwise stopped by the controller/owner of said agent. They have their own identifiers, attributes, functions and states that allow them to interact with other agents or computer networks (TCP/HTTP, EVM blockchains, other blockchains/networks).
Components: Components can be viewed as packages of code to be created and implemented inside of agents/agent services in order to give the agent(s) specific attributes and abilities. See Core Components to see which components make up an agent by default.
Registry: The Component Registry is contained in the IPFS registry and is the catalog that stores all the components that have been published to it for re-use of the code in future agents/services
Agent Service: An agent service is an application that utilizes multiple agents to build a peer to peer network (Multi Agent System) that executes or communicates in some way together. Agents within an agent service will implement a “finite state machine” component that gives each agent in the network a state representation of the rest of its peers within the agent service in order to execute arbitrary logic based on said state.
Finite State Machine (FSM) App: The core component inside an agent that defines a decentralized app implementing the business logic of the agent service. FSM Apps implement the underlying mechanisms that allow agents to synchronize their internal state with the rest of the agents in the service.
Further, agent services along with the agents that participate in them can be designed to perform any number of tasks in the space of multi party computation (MPC) while still being highly modular and composable to the rest of the software ecosystem. The table below is a quick visualization comparing different types of distributed system software applications and their various capabilities.
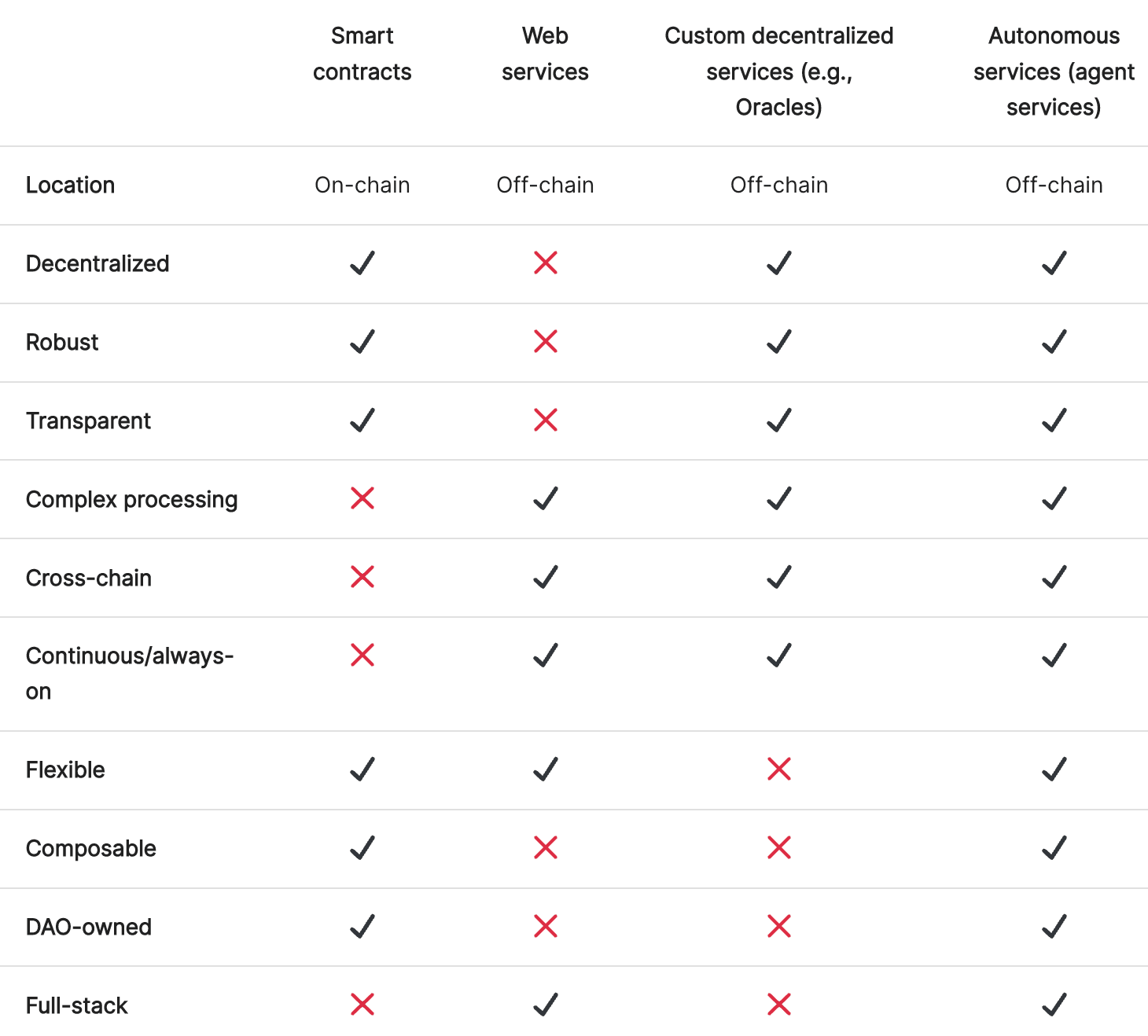
The biggest takeaways from above is that Open AEA + Open Autonomy have by default, the flexibility to build apps that interact with all other systems if desired, pick their own execution environments for decision finality (state minimized consensus gadgets) and over time will continue to improve in their performance as the frameworks mature.
Limitations of Blockchains for ML
So, you want to run computationally intensive machine learning models partially/fully on a distributed virtual machine (VM) (aka a blockchain) and maybe build some sort of smart contract based DAO around it?
The problem is that monolithic blockchains are not Turing complete execution environments capable of large compute/throughput and instead are quasi-Turing complete because of how a blockchain’s VM specification is designed around its various clients. Gas consumption measures the compute resources used in a given transaction/block based on the instruction set (opcode) cost model that makes up the blockchain’s VM specification.
There is only so much gas able to be consumed over a given period of time (or within one block) which limits computational throughput and storage capabilities making more resource intensive operations either impossible or too expensive currently.
The same can be said for existing modular blockchain architectures which have more efficient execution environments than monolithic chains as a result, but are still limited in certain operations that are too expensive/impossible.
Training vs Inference
An important distinction to be made is how the training/inference steps of a given model differ from one another. This will shed light on what specific steps in the whole ML pipeline can be distributed amongst a decentralized and fault tolerant network and which steps need centralized execution to work (at least for right now and the foreseeable future).
Resources needed for the inference step consist of a single forward propagation of the model (non-iterative). First the input data is fed into the input layer of the network and typically there is some pre-processing of the raw input data needed but not always.
Once the input data is fed into the model it is then transformed at each layer given the weights and biases that were calculated in the training process (these are now constant). When the input has been fed through all the layers of the model it provides its output.
There can also be some post-processing steps for the output depending on how different model architectures vary. Based on the size of the model itself and the size of the data it is using in the inference, it can be quite difficult/impossible for average performing desktops/laptops to run the inference of a model that is on the larger end of the spectrum, let alone training.
Nonetheless, many existing models fall in the category of their inference step being possibly computed with many execution environments (even slower and less powerful ones) while their training must remain in centralized hyper-efficient execution environments.
Model training is a much more computationally intensive task than that of a forward pass (inference). Training a model requires many iterations and calculations that are not present during the inference step. Namely, backpropagation, which involves gradient calculations of the loss function with respect to each model parameter.
Gradient calculation and parameter updates are very expensive individually and also have to be done iteratively to train the model through multiple epochs. Training includes other steps and can be generally be broken down by:
- Modifying/preparing the dataset being used for training the model to be used as input into the model.
- Determine how to batch the training data splitting it into portions for each iteration of the training epochs.
- Epochs
- a. Forward pass of the model using current batch
- b. Calculate the loss function between model output from this epoch and the known correct output
- c. Backward pass (backpropagation) to compute gradients of loss function and adjust the model parameters
- d. Update model parameters (weights and biases)
4. Save the trained model to be used after it is done being trained to the performance desired.
The above high level explanation does not include extra steps often included in existing ML models such as hyper-parameter tuning and other optimization algorithms that can be used within the model.
Nonetheless, training is clearly more involved than doing a single forward pass to get a model’s output in the inference step. Hence, why it is significantly less overhead to prove the inference step using zkML and/or make decentralized collaborative ML applications with multi party computation.
This is where agent services offer an alternative solution that allows for very computationally intensive applications (for example ML models) to benefit from the utility of distributed systems, decentralization, fault tolerance, and co-ownership/operation without limitations placed on current blockchain systems.
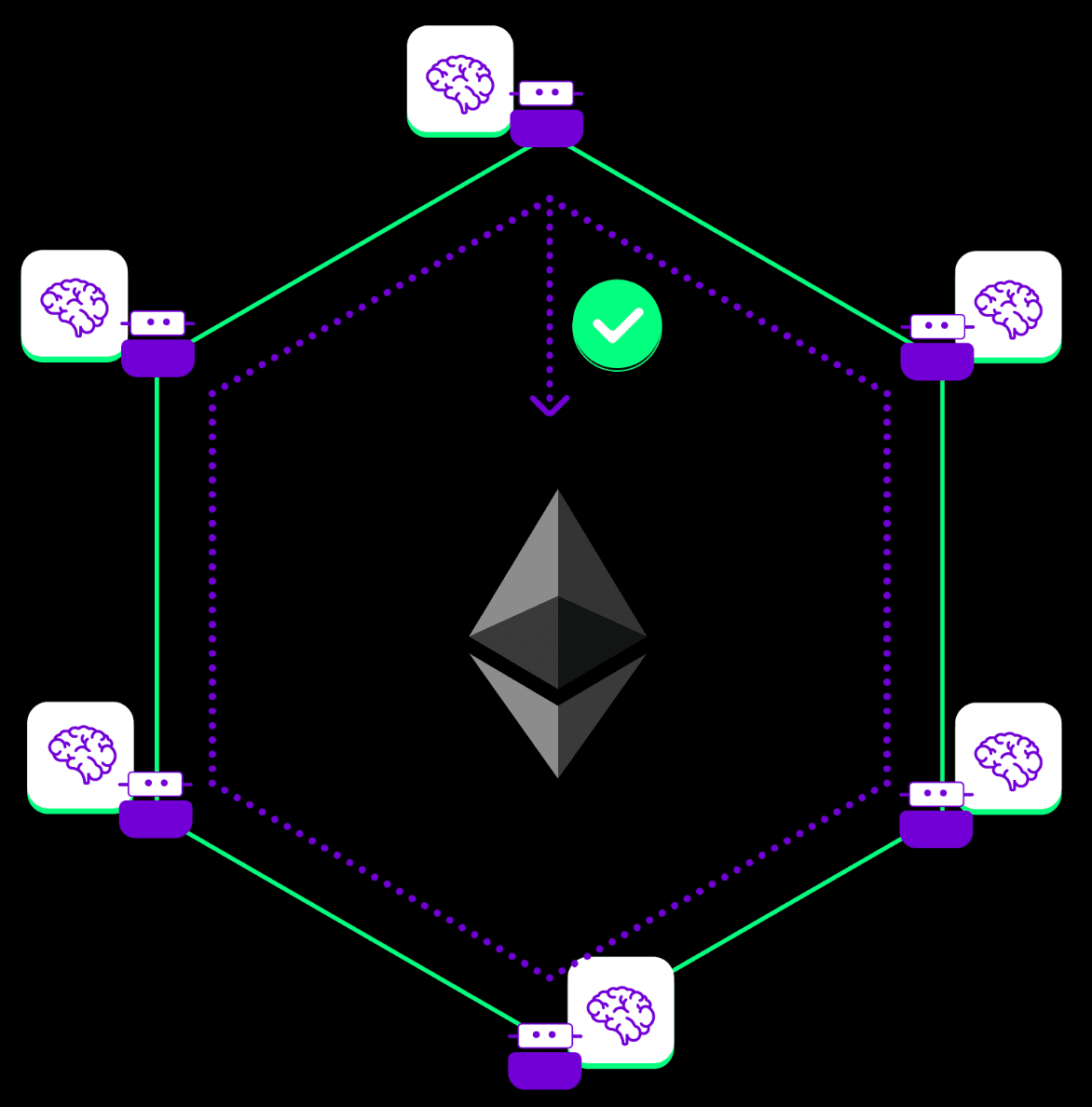
The image below is a visualization of what it would look like for an agent service to operate peer-to-peer amongst agents doing very computationally intensive tasks off-chain (for example an arbitrary Python runtime).
Thereafter the agent service will have its agents come to consensus. This can happen using Ethereum/blockchains as the source of finality or entirely by off-chain means depending on the agent service design (the example below depicts Ethereum as the layer used for finality/consensus).
Distributed Machine Learning
Assuming we put decentralization, fault tolerance, transparency, privacy and other positives to making distributed ML applications on the sidelines for now, with distributed machine learning applications there are two generalized categories of technical benefit to define. Distribution of ML models does not only create benefits, but also creates a new problem of now needing to “synchronize” the state amongst all of its distributed actors (discussed below).
Run.ai has a very well written article breaking down distributed ML parallelism here.
1. Data Parallelism: “In this type of distributed training, data is split up and processed in parallel. Each worker node trains a copy of the model on a different batch of training data, communicating its results after computation to keep the model parameters and gradients in sync across all nodes. These results can be shared synchronously (at the end of each batch computation) or asynchronously (in a system in which the models are more loosely coupled).”
2. Model Parallelism: “In model parallelism, the model itself is divided into parts that are trained simultaneously across different worker nodes. All workers use the same data set, and they only need to share global model parameters with other workers — typically just before forward or backward propagation. This type of distributed training is much more difficult to implement and only works well in models with naturally parallel architectures, such as those with multiple branches.”
3. Synchronization: There are several ways to go about model synchronization, the most noteworthy algorithms being in the “all-reduce” category. In all-reduce designs “the load of storing and maintaining global parameters” is shared amongst all actors.
These 2 principles of parallelism also apply fundamentally to development of distributed ML apps using agent services built with Open AEA + Open Autonomy. Only now, instead of a single entity working in a centralized cluster of their choosing utilizing distributed ML data/model parallelism, it will now be a network of agents in an agent service doing so where adversarial economic incentives are introduced.
The difference between decentralized ML applications as compared to distributed but centralized ML is the need for decentralized ML apps to design around adversarial actors attempting to gain or exploit the system in some way because no trusted party is assumed. Whereas with centralized distributed ML the cluster(s) is all being controlled by a trusted party/group so no restrictions are needed to stop adversarial attacks.
semi-related note: many of the algorithmic breakthroughs used in today’s cloud computing resource management systems Borg & Omega research by Google especially around “shared states” and “optimistic concurrency” will transfer very well to making efficient shared states in the form of FSM components for Multi Agent Systems & Agent services as a result.
Co-Owned AI/ML Using Agent Services
Co-owned AI put simply, is “AI that is jointly owned and controlled by multiple parties”. In this case, distributed ML applications can be built with agent services leveraging the peer-to-peer functionality of agents as well as the service’s “shared state” that each agent is aware of. The agents are continuous runtimes (Python, but could be other languages) that can execute their functionality with any number of different hardware/OS configurations as long as the frameworks support it.
Given a network of agents executing some Python code making up a service, one can design applications to make agents collaborate on the same/similar computationally intensive tasks (ML for example) to split workloads amongst a network, or have agents work on different tasks that are part of some net operation the agent service is designed to accomplish (another design option for ML based agent services). These designs allow for the formation of distributed systems reliant on the sum of their agent actions and the consensus on those actions to make distributed ML applications possible.
Potential use cases for single service design:
- “Federated” learning between multiple ML models that all do the same task, where each agent in an agent service has its own data, weights, biases and local model they train. Then after a training epoch is completed the resultant “shared” model is constructed in some way by the aggregation of each agents’ model. This could be 100% egalitarian where each agent contributes equally to the shared model, a competition for who impacts the shared model the most, or some other arbitrary parameter determining the training contribution of each agent (local ML model) to the shared model inside the FSM component of the agent service. Works for both classification and regression tasks.
- “Ensemble” learning between multiple potentially different ML models that can do different tasks, where each agent has its own individual model and the shared model forms some output based on the consensus of what each agent (different ML model) can do per the guidelines of the agent service, to impact the output of the shared model. Works for both classification and regression tasks.
- “Co training” between several ML models running the same task (potentially different models) on individual agents in a service. The inferences of other agents are then shared with the individual agent and used as new training data. Works for both classification and regression tasks.
- Many others exist both documented and in someone’s imagination yet to surface on the internet.
Potential use cases involving multiple services:
- Hybrid co-owned AI applications that have multiple agent services doing the same/different things to accomplish some result(s).
- Networks of co-owned AI that consume each other’s ML services making autonomous ML ecosystems.
Problem:
There is virtually no economic incentive to participate in several valuable co-owned AI use cases unless there are elements of privacy targeted at the data and the ML model’s themselves, assuming the MLaaS businesses that would create those models need them to be proprietary in order to profit.
Maybe zkML and Secure Multi Party Computation (SMPC) can save the day? There is only one way to find out ;)
Taking a step back to look at why this is the case, the economic incentives become more clear when one thinks about the fundamental value of data itself, and the costs associated with collecting/creating/maintaining datasets and the most computationally intensive part, running the models.
The reason that a company like OpenAI considers it worthwhile to build and allow use of extremely large transformer models (GPT-3 & 4) is because firstly, the models are not open source making them proprietary.
Second, their permissioned API makes it incredibly hard to reverse engineer and/or recreate the model, which is by design.
Third, the centralized cluster they are training/running the model in as well as feeding/maintaining their data in, is vastly more efficient than trying to make a decentralized equivalent.
As a result, all the money/time they spent training the model to its current state is now a worthwhile economic investment for the business and its shareholders as long as the model stays proprietary. In the case of trying to do something like GPT-3 & 4 open source the entity that decides to pay the money to train a large model has no way to return an investment from those costs if their data and model are not kept proprietary.
In the case of a privacy preserving decentralized environment for a large collaborative ML pipeline similar in function to GPT-3 & 4 that is kept proprietary, the computational overhead of using certain SMPC techniques, compared to a centralized cluster, is not practical at this point especially for data and training tasks. This is because of how much extra time is needed and how much more expensive the computation would be on top of the already expensive large ML model given current MPC and cryptography solutions today.
As the zkML and distributed/decentralized ML space matures we will see the number/size of ML models that can reasonably be proven using zkML increase. The number/size of models that can be decentralized while maintaining privacy, efficiency and scalability will also increase.
This line of thinking can be cascaded into many other ML business models (MLaaS), proprietary analytical tools and various processes around maintaining/improving outcomes.
Generally one can expect that a financially rational actor will not do computational work for free. This brings us into the discussion of how one can build distributed & decentralized ML apps that leverage privacy features in order to preserve economic incentives for the actors working within them, who would otherwise not participate.
zkML/SMPC Use Cases For Agent Services
Single Agent zkML Applications
A single Open AEA agent is capable of reproducing existing zkML use cases involving a prover and a verifier party for a generalized non-interactive ZKP such as what is done in zkMNIST. The agent would take on the responsibilities of the “back-end” in that it runs the MNIST CNN classifier (training + inference) and provides its inference along with a groth16 SNARK proof showing computational correctness to the client who can then verify the proof in a smart contract on chain.
The client interacts, providing an input to the MNIST classifier within the agent and can then choose to verify the generated proof to check the model’s output. The client would use a verifier smart contract on some blockchain (in zkMNIST’s case, ETH Goerli testnet) where they will send the proof they want to verify. This idea could prove potentially useful in the design space of agents but also could be done with a simple server/client web app as it is originally implemented. The same can be said for all other applications involving a non-interactive prover/verifier setup like zkMNIST.
What Open Autonomy Offers
The way that Open Autonomy differentiates itself is in building agent services to accomplish certain tasks with a network of actors (agents) that would otherwise have to be designed from scratch under a different stack and would potentially not have full composability to the rest of the software ecosystem. All the foundational operations needed for building Multi Party Computation (MPC, both secure & transparent) systems of virtually any kind are already built out in the Open Autonomy framework or can be added in as needed.
Agent Service for generating ZKPs across a network of agents
To further expand on the single agent idea above, one use case to look at building could be making an agent service where each agent in the service runs its own prover making up a “prover network” allowing for proofs such as SNARKS, STARKs or other generalized proofs to be generated. These proofs could be generated in parallel then later combined to distribute larger proving workloads across multiple provers or by some other means using the network of agents. This would be useful in examples where computational tasks that are quite large (for example ML models) would be impractical or impossible for a single machine to prove by itself.
Potential Benefits:
- Privacy apps of all kinds using the supported proof system(s) can use this “Prover as a service” network and economies can then be built around the agent service as a result.
- Scalability: multiple provers working in parallel, resource scheduling algorithms, etc.
- Added fault tolerance: multiple provers cross checked on their output proof for correctness.
ML Agent Services
Returning back to co-owned AI, for a lot of the interesting use cases to work we need cryptography to keep some things private (namely data and/or models). This is where zkML and SMPC come to save the day! One can build agent services using the principles of zkML and SMPC to make applications for federated learning and ensemble learning in a decentralized environment.
Federated Learning using SMPC/zkML
An example of federated learning as it applies to agent services could be a global image recognition model (for example a basic CNN for MNIST data) made up of several local models within the service’s agents. This global model of the agent service and the local models that it aggregates take in a 28 x 28 image of handwritten digits and then returns a number 0–9 as its inference.
Each agent in the service will have its own local CNN that does 28 x 28 image inputs to 0–9 integer prediction outputs and its own local data set that could be a complete copy of the MNIST data set or perhaps a unique dataset. Each agent trains their local model on their local dataset to initialize it or they can perhaps use a pre-trained model instead.
Given a certain cyclical feature to the agent service (this could be time/iteration based epoch or something else) the network of agents will share “model updates” periodically based on the agent service’s logic.
Model updates are the tedious part of this whole design as we now need to find a way to share the new weights and biases of each agents’ local model with all other agents in a way that does not reveal each agent’s full local model assuming there are adversarial/malicious actors able to participate in the agent service.
For example, one or a subset of the agents participating can try to reverse engineer other agents’ trained local models, attempt to be dishonest or try to gather private data from the other agents (both of which, we need private in order to incentivize agents to spend compute power training/participating in the service in the first place).
In the case of SMPC MNIST, each agent when it comes time to do a model update within the agent service, will homomorphically encrypt their model updates using a scheme such as CKKS.
This article will not cover FHE schemes in depth but in short, for this example each agent will start out by committing to a shared public-private key pair for the agent service to be used in threshold decryption of the shared model after operations of the encrypted model updates are complete.
The FHE allows for operations that need to be done when constructing the global/shared model to take place privately amongst the agents by combining each agent’s encrypted model update together to a computed average. Each agent both sends and receives each of their encrypted model updates and then afterwards, reconstructs the global/shared model based on the computed average from the homomorphically encrypted model updates they received.
Once the computations are complete and each agent has its own encrypted average model update from the SMPC protocol the global model can then be decrypted amongst the network of agents assuming a threshold of signatures was met.
From this point the shared model that was decrypted can be designed as a zkML model making either the shared model private and keeping its inputs public or vice versa. In the example of SMPC MNIST the idea is to keep the shared model private while still allowing proof/verification that its execution is sound.
There are some significant limitations in the scope of ML models that can reasonably work in this SMPC ML idea which is based on how expensive the cryptography system is, how performant computer hardware is and how big the ML model is.
Models as big as GPT are still far out of reach with today’s technology (100B+ parameter model) but smaller models have potential usage right now.
Another core feature to add to a decentralized/private federated learning protocol built with agents would be certain parameters and rules set in place for agent participation, namely a governance quorum for global model updates as described above using threshold cryptography, but also other things perhaps. For the sake of length I will not go into more detail, but imagine the possibilities!
Note: This agent service design is extensible to other ML model types outside small CNNs for MNIST predictions even if it is not able to be used in the largest models of today.
Ensemble AI using zkML
An example of ensemble learning as it applies to agent services could be a global ML model for macro economic sentiment analysis that takes into account various geographical locations, economic indicators (inflation, standard/cost of living, etc), price data for many asset classes, open interest data across several asset classes and perhaps other data. Each agent takes on a role and builds an associated local model (does not necessarily have to be an ML model) for their agent to do training and inference based on said role (data + task).
Assuming we have an agent service made up of 3 agents where all 3 agents have different local ML models it will not be plausible to do SMPC in the same way as was described above with federated learning where the models are the same. Instead, the agent service can have all of its agents construct their own ZK proofs from the execution of their local model (assuming the model is not too large to be proven in a reasonable time period) along with their respective outputs, which are then both relayed back to the shared model.
In this respect the “ensemble” of AI run through the agent service serves as an aggregation of several potentially different models. Further, given there are existing agent services, for example ones that run global federated learning models, those agent services can then be aggregated with an ensemble AI agent service and proven if the time to prove permits it being usable as its zkML equivalent.
Demo Specification (WIP)
The demo using Open Autonomy will focus on using SMPC + FHE within an agent service to build a distributed MNIST CNN classifier with a network of Open AEA agents that run their own private local models. These private local models run by the agents will then make a global model that an agent service uses for inference without giving away local training data from each agent or the weights/biases of their local models.
A full implementation will be done later and open-sourced/benchmarked, but for the time being I will focus on the key aspects of the agents’ peer to peer functions and the finite state machine app that makes up the agent service in the form of a partial specification.
Setup Configurations:
For the sake of simplicity let’s assume each agent has a pretrained CNN classifier trained on the MNIST dataset. This model has 2 convolutional layers and 3 fully connected layers adapted from pytorch’s MNIST classifier example just like what is used in zkMNIST.
Blackboxing the rest of the agent design, we know that the agent needs to perform training and local execution of its ML model and perform model updates to the agent service’s global model. Of course, the specification is much more involved so there is more detail below starting with what the agents will do and ending with a rough draft for the finite state machine specification.
Agent:
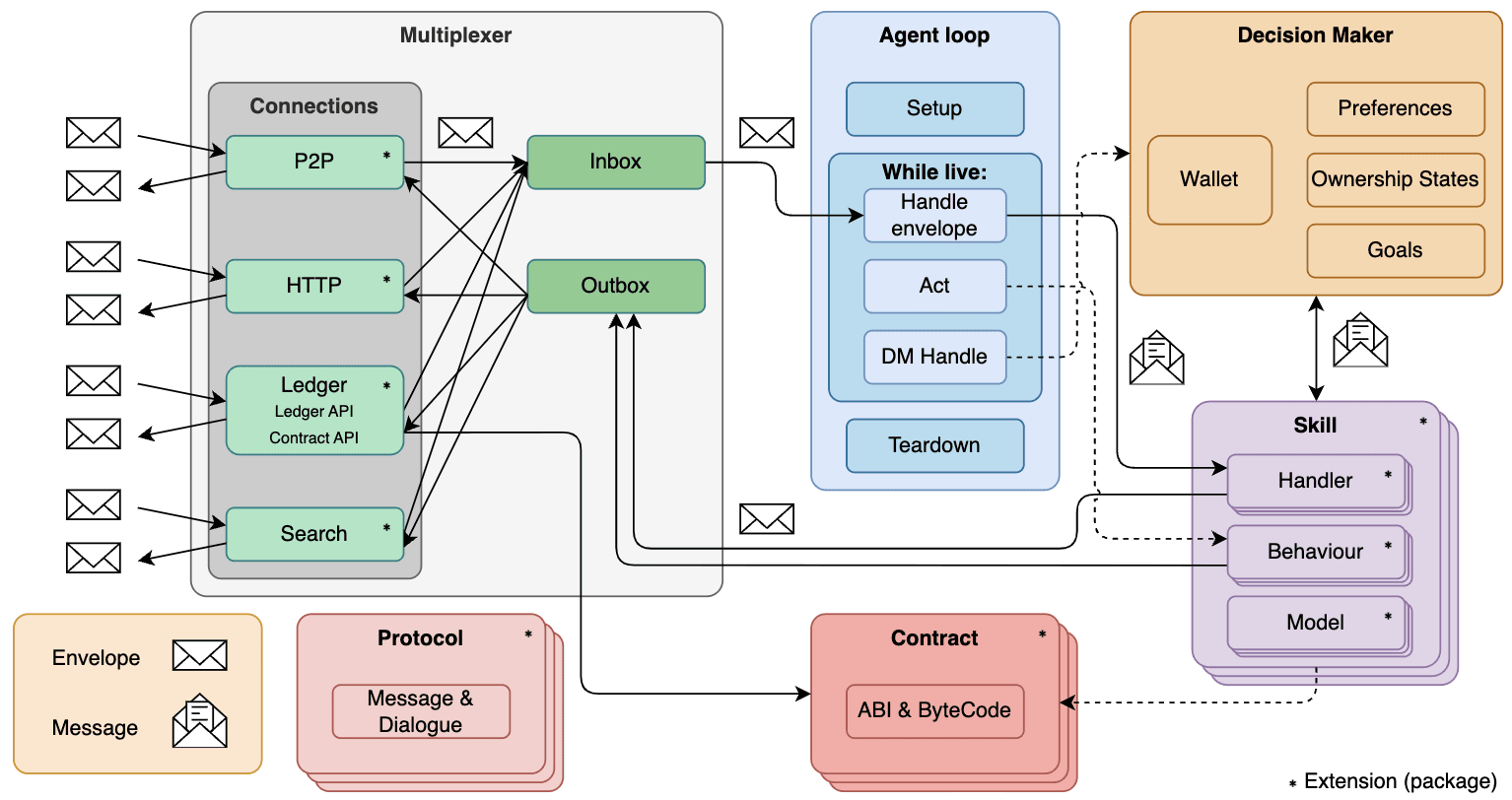
In the case of SMPC MNIST, each agent will need “Skills” for each operation that constitutes local/global interactions.
Local agent actions example:
- Setup / Init
- Load / Remove Data
- Set training parameters (time, iterations, batch size, etc)
- Execute training of model based on training parameters and loaded data
- Encrypt the local model update using CKKS FHE scheme
- Forward pass (local inference)
- Teardown
Global agent actions example:
- Key generation for the CKKS scheme, each agent generates a part of the private key used to generate a public key for threshold signatures needed to decrypt the shared model.
- Send homomorphically encrypted model updates to all other agents in the service
- Receive encrypted model updates of the other agents, where each agent receives (N-1) updates, where N is the number of “active” agents in the service.
- Compute the average of the homomorphically encrypted model updates given by all agents
- Run threshold decryption between agents in the service in order to decrypt the shared average model computed over the homomorphic representation of each agent’s model updates.
- Finalization of the shared model update across all agents, the latest decrypted average computed model is committed as the new shared model for use in the agent service.
Agent Service:
Making an agent service from scratch
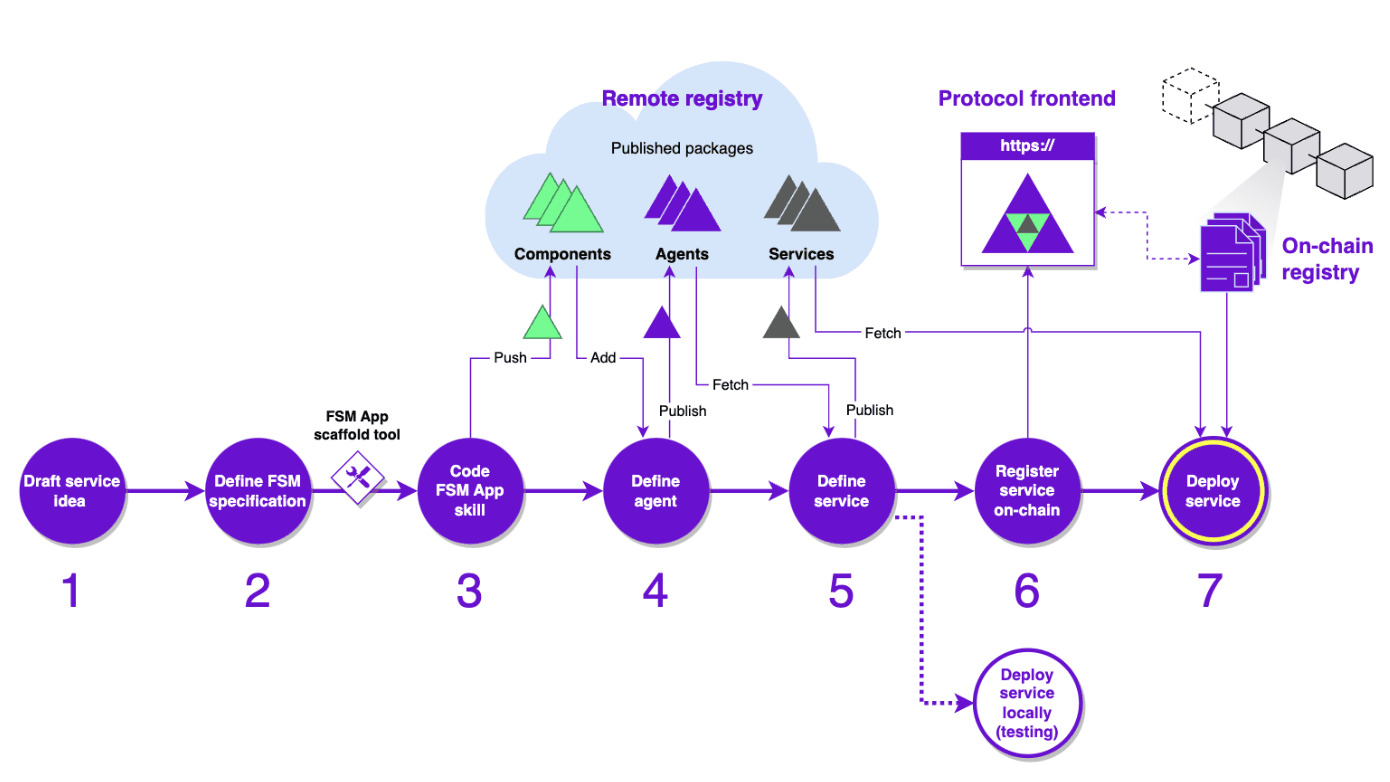
Given the breakdown of agent actions above we can now begin to form a specification for the agent service and the resultant finite state machine app used for its operation.
1. Registration / Init State: This is the state where the service can set an allotted amount of time where agents can join in (2 weeks for example) before the first state transition into a training phase. Another example could be until it reaches an allotted number of agents. The global model has some initial state at this point and agents could perform whatever local actions they want. Before initiating the state transition to the training state the key generation process must be performed between all the agents in the service for use of the CKKS FHE scheme and threshold decryption of the shared model. This can happen based on time or number of participants a single time or in rounds. Each agent generates part of the shared private key for the use of homomorphic encryption operations used to keep model updates hidden. Users of the agent service can use the global model but it won’t do anything as it is just initialized and agents can not perform any model updates in this state.
2. Training state: In this state, agents can freely decide what they would like to do within the guidelines of their local actions. The main goal in this state is for all the agents to start training their local models, or perhaps load a pre-trained one in order to prepare for the state transition to model updating of the global model. Each agent also has the ability to homomorphically encrypt their local model update at any given point in the training state. Either this encrypted model update value can be used pre-committed by a given agent or computed as part of the state transition to updating the shared model. During the training process the global model is still in the previous state that it had, this could be the init state or the latest state from the previous global model update. For this example, we will say that every 24 hours the training state will transition to the global model update state.
3. Global model update state: In this state, agents first calculate their local model’s homomorphically encrypted equivalent. These local encrypted model updates for each agent are then sent to the other agents in the service. After each agent has its set of model updates from the other agents in the service, these updates are used by each agent to compute the average of the model updates while the data remains encrypted. After the average model update is computed among all agents the decryption of the computed average shared model can be made assuming the threshold for decryption is satisfied by the agents in the service. This entire process can also be broken down into sub states for more clarity (below).
- a. Calc/send & then receive encrypted model updates: each agent must calculate and send its local model updates using the homomorphic scheme, CKKS, to every other agent. As a result every agent must receive all other existing agents’ encrypted updates before a transition to model update average calculations can occur.
- b. Calculate model update average: Based on the homomorphically encrypted model updates each agent receives, an average must be computed among all model updates to arrive at a homomorphically encrypted average model update that each agent now has. All agents must complete this step before transitioning to the threshold decryption step
- c. Global model decryption: each agent, assuming the state transition from “Calculate model update average” to this state is valid, now must take the computed average model updates it, computed in the previous state and perform decryption on the averaged model updates with their individual key share assuming the decryption threshold was met.
- d. Global model update: after decryption has taken place for all participating agents the global model users interact with when facing the agent service is updated based on the decrypted model computed by the agents.
4. Return to the training state / repeat (24 hours of the training state, followed by the transition to the global model update state in this example)
NOTE: For any given state or sub-state in this process, realistic time restrictions would be given for each operational step so that if the agents reach a dead state, they will revert back to the training state or a perhaps a teardown state that reverts back to the “Registration / Init” State after a predefined amount of time. The global model update would then be labeled as incomplete and no update would occur.
Agent Service Governance:
As for how governance could be built into this agent service to make it more verbose for use in a live environment, each agent could vote and have the service come to a minimum quorum when updating the global model that goes beyond just the threshold of signatures needed for decryption.
The same can be said for cases where agents go offline during the training state/other states. In a live environment it’s likely that agents that were considered “active” parts of the service during a given state might go down whether intentional or not. The service should cover those edge cases and provide incentives for well performing agents over other less performant agents.
Here is what the FSM Specification file (fsm_specification.yaml) would look like:
alphabet\_in:
\- START\_TRAINING
\- DONE\_TRAINING
\- DONE\_UPDATE
\- NO\_MAJORITY
\- UPDATE\_TIMEOUT
\- TRAINING\_TIMEOUT
default\_start\_state: RegistrationState
final\_states: \[\]
label: packages.valory.skills.smpc\_mnist\_classifier.rounds.SmpcMnistClassifierApp
start\_states:
\- RegistrationState
states:
\- TrainingState
\- UpdateGlobalModelState
\- RegistrationState
transition\_func:
(RegistrationState, START\_TRAINING): TrainingState
(TrainingState, DONE\_TRAINING): UpdateGlobalModelState
(TrainingState, TRAINING\_TIMEOUT): RegistrationState
(UpdateGlobalModelState, DONE\_UPDATE): TrainingState
(UpdateGlobalModelState, UPDATE\_TIMEOUT): TrainingState
(UpdateGlobalModelState, NO\_MAJORITY): TrainingState
Comparing zkMNIST and SMPC MNIST
When comparing the similarities, differences and tradeoffs between using ZKPs and SMPC for private/distributed ML applications we can look at where they are applicable, efficiency, complexity, security and scalability.
zkML, in reference to the proof generation of the inference step of a given model, allows the model’s output to be verified by its user without making either the input or model parameters public.
SMPC can jointly compute specific steps in the ML pipeline such as inference or allow for collaborative ML MPC applications such as the SMPC MNIST agent service example above while preserving privacy of individual data/models.
The way in which privacy is achieved using SMPC is fundamentally different from that of ZKPs when they are standalone from one another. zkML privacy is based on the “soundness” of the proof system being used where the cryptography is assumed to be unbroken.
With SMPC in its basic form, privacy is achieved by relying on an honest majority and the difficulty associated with colluding amongst a network if a certain minimum set of honest actors exist (aka “honest-majority” security) with simple secret sharing algorithms.
There are ways in which one can expand beyond honest-majority security into more robust implementations (dishonest majority security) using methods developed specifically for SMPC as described in the SMPC MNIST example above, where malicious actors are assumed.
In the case of the SMPC MNIST example, homomorphic encryption is used alongside MPC to keep the local models and data private where even a majority dishonest/malicious network of agents cannot discover other agents local model parameters or data exactly from the shared model. The design space of using ZKPs, homomorphic encryption and other cryptographic primitives within SMPC systems is very interesting and promising as far as future applications to decentralized ML/AI.
Fundamentally the security of ZKPs is more robust & harder to break the privacy of for the purposes of hiding the model with a public input or hiding the input to a public model as compared to honest majority SMPC. The tradeoff is that computational requirements are much greater for zkML tasks than that of today’s basic SMPC systems.
The security of honest majority SMPC is less robust compared to the properties that zkML can yield as the privacy of the MPC network can be broken if there is enough collusion amongst its participants assuming no added properties beyond secret sharing. Performance comparisons to zkML and security differences become more unclear and hard to define as the SMPC protocol in question becomes more robust (dishonest majority security).
As a result of becoming more robust the SMPC protocol adds computational and/or communication overhead compared to basic SMPC systems as a result. I have yet to find much public research or benchmarks on the niche topic of zkML vs (dishonest majority security) SMPC ML. That being said, one of the goals of this research is to provide proof of concepts and benchmarks for several different aspects of these systems to compare and contrast.
Another point of significance is the scalability trade offs between zkML and SMPC. zkML is limited by the speed of the proving and verification processes for a given task, whereas SMPC is limited by communication overhead as the size of the party increases as well as the cryptographic techniques used within the SMPC protocol to provide a certain level of privacy/security.
For now, I expect that for smaller ML models and computation that generally can be run both on a client’s machine locally or on an edge device even, rather than exclusively on a server entity, will see large development in the zkML space.
This also includes computationally intensive but dishonest majority or maliciously secure and private SMPC ML applications that leverage things such as ZKPs, homomorphic encryption, or other cryptographic techniques within them which significantly increase computational requirements (they are most plausibly used in smaller models similar to that of zkML).
SMPC for decentralized ML systems has the potential to play a significant role when it comes to large models that cannot be easily proven, run inference locally on client, or even store on an average high end client desktop as there are some cases where computational overhead can be removed by adding some trust to the system.
New developments / breakthroughs in the software space of cryptography and MPC along with hardware will continue to open up new possibilities for designing more accurate, fair, transparent, private, and decentralized AI services for humanity. It is just the start!
Conclusion
The reasoning behind this research article is to break down how zkML and SMPC can be applied to designing co-owned AI systems more generally, and more specifically how one can build applications in this space using the Open AEA + Open Autonomy multi agent system frameworks.
The reason these topics are important is, one, because of how the current landscape of AI businesses are constructed (opaque, permissioned and centralized). Two, collaborative ML models and networks of ML services running autonomously in decentralized distributed systems will end up, long term, being more performant and providing more value than that of their isolated / centralized counter-parts.
Build privacy preserving and better performing ML systems in a more open/competitive market that many people have power over with less permissions along with more decentralization. Don’t build skynet plz 😉
Related Open Source Software Tools
ML + Privacy + MPC + Cryptography
- EMP-zk
- Secure and Private Data Science with PySyft
- Federated learning project that uses PySyft, PyVertical
- IBMs FHE toolkit with ML examples
- Privacy preserving ML with CrypTen
- SecureNN
- Multi Agent Reinforcement Learning / MARL
- Zama.ai
- Rocky Bot, validityML by Modulus Labs
- Secure 2 party computation engine, tandem
- HoneyBadgerMPC, SMPC blockchain application
Sources
- GPT4 :)
- Intro to zkML by Worldcoin
- Awesome-zkml by zkml-community
- Cryptographic Primitives by Remco Bloeman
- Simple Explanations of Arithmetic Circuits and Zero-Knowledge Proofs by Hadas Zeilberger
- zkML Tutorial by @horacepan @sunfishstanford @henripal
- Distributed Training by run.ai
- Co-Owned AI by Valory
- Federated Learning by Google AI
- Co Training, Cornell Research
- Open AEA documentation
- Open Autonomy documentation